
In the shadow of SpaceX’s spectacular launches and the endless parade of satellite constellation announcements, a quiet crisis is brewing. It doesn't grab headlines or inspire Netflix documentaries; instead, it surfaces as missed launch windows, spiraling delays, and satellites failing silently in the unforgiving vacuum of space, where no rescue mission can reach them. It's quietly acknowledged—though notoriously difficult to measure—that roughly half of all small satellites experience failure. But you'll rarely see that statistic splashed across a news site.
I've spent years seeing talented, well-funded startups step eagerly into the space sector, armed with impressive PowerPoint satellites and optimistic timelines—only to run straight into a harsh, often humbling reality. That collision isn't just messy; it's costly, deeply discouraging, and perhaps most frustratingly, often entirely preventable.
This isn't due to a lack of intelligence or sweat equity—Silicon Valley is brimming with brilliant minds who put in long hours. Rather, it's about a fundamental mismatch between software thinking and hardware reality. This became clear during my experiences as a CTO in Y Combinator (S16 and W21), where my mentors, Sam Altman and Geoff Ralston, emphasized the value of moving fast.
But in space and defense technology startups, speed alone isn’t enough. Founders must also carefully manage existential risks, calibrating their pace to ensure they're moving at the right speed—not simply as fast as possible. As YC founders and Silicon Valley investors increasingly venture into space and hard tech, balancing agile innovation with rigorous, aerospace-grade risk management isn't just beneficial—it's absolutely critical.
It's about understanding the hidden fragility that aerospace veterans know intrinsically but newcomers often discover too late and at great expense.
Let's dive into why so many smart people keep making the same costly mistakes up there in the void.
The Underappreciated Fragility of Space Hardware Supply Chains
Vendor Sourcing Is Mission-Critical
In software, if a library or service becomes problematic, you can usually find an alternate solution or write your own workaround. In space hardware, dependencies are far more absolute and unyielding.
Space hardware often depends on single-source or highly specialized suppliers. If even one vendor slips, the whole schedule unravels. Aerospace parts like propulsion valves and radiation-hardened electronics have few qualified manufacturers, and lead times can stretch many months. Export controls (ITAR/EAR) further constrain options – U.S. regulations can delay or block foreign-sourced components, making quick swaps nearly impossible.
In short, you can't simply "order from another supplier" when only one company on Earth makes that space-grade part.
Real-World Consequences of Supplier Delays
Unlike software launches, missing a launch window can set a program back by months or years. Space mission timelines are unforgiving – if hardware isn't ready, the rocket doesn't wait.
The U.S. Space Development Agency had to push its satellite launch from spring to late summer 2025 because critical components weren't delivered on schedule. Even NASA's flagship programs have felt this pain: the Artemis III Orion capsule faced an 11-month delay due to supplier struggles. If the United States government—the world's leading space power—isn't immune to supply-chain issues, your startup certainly won't be either.
In planetary missions, a delay can mean waiting years for the next alignment. ESA's ExoMars rover mission infamously missed its 2020 Mars window after parachute test failures and an electronics glitch that required hardware to be sent back to the supplier. These examples show how a single vendor issue or subsystem flaw can cascade into multi-year delays.
No "Updating in Production" for Satellites
In web software, pushing fixes after launch is routine. In orbit, it's a luxury you often don't have.

Once a satellite is up, the hardware is literally out of reach – you can update software to an extent, but you can't solder a wire or swap a faulty chip. The idea of rolling out hardware hotfixes in space is (for now) mostly science fiction (aside from rare cases like the Space Shuttle servicing the Hubble Telescope to fix its mirror – an expensive exception proving the rule).
Most satellites must work right the first time because if something breaks in orbit, there is usually no second chance. This finality forces a mindset alien to "move fast and break things" culture: you must get it right before launch, as bugs and glitches can mean mission failure with no hope of repair.
Smallsat Integration Pain Points When ICDs and SMAD Are Neglected
Skipping the Details in ICDs
An Interface Control Document (ICD) is supposed to spell out every connection and spec between subsystems – power pins, connector types, data protocols, physical envelopes, you name it. In practice, some smallsat teams treat ICDs as a formality, leaving out "obvious" or cumbersome details.
The result? Late-stage integration nightmares: connectors that don't mate, power interfaces that magic smoke components due to mis-voltages, communication links that time out because of unaccounted latencies. Over-simplistic ICDs that gloss over real-world specifics inevitably lead to misaligned hardware and surprises during assembly.
A hard lesson from aerospace veterans is that nothing is too trivial to document. As NASA's own integration experts advise, start hardware integration early and validate every interface – don't assume things will just fit together.
Building a Smallsat Bus – A Sourcing Gauntlet
Crafting a small satellite (bus + payload) is like assembling a puzzle where each piece comes from a different specialist. Often times, there are only a single vendor that makes a critical hardware component. Consider the bus (the part that keeps the satellite alive and stable):
- Reaction Wheels: These tiny momentum wheels orient the satellite. Only a few vendors globally make space-qualified reaction wheels for cubesat-class spacecraft, and if one supplier's wheel has an issue (recall the many CubeSats that tumbled helplessly due to wheel failures), there's seldom an easy substitute on the shelf. Lead times can be a year or more for a high-reliability wheel assembly.
- Attitude Determination and Control System (ADCS): Often a bundle including star trackers, sun sensors, magnetometers, and software. Companies like Blue Canyon or Hyperion might provide an off-the-shelf ADCS, but integrating it isn't plug-and-play – you must ensure the sensor alignments and data formats match your flight software. If teams neglect the calibration and alignment info in the ICD, the satellite might think it's pointing one way when it's not. Think of your worst NVidia GPU driver nightmare times ten.
- GNSS Receiver: A good space GPS/GNSS unit for orbit determination can be export-controlled – certain high-altitude capable GPS units fall under ITAR. A naive team might order a COTS GPS unit only to find it shuts down above 18 km due to built-in limits or that it can't legally be shipped to their international partner. Choosing the right space-qualified GNSS (and securing the licenses for it) is a project unto itself.
- On-Board Computer (OBC): The satellite's brain – often a radiation-tolerant microprocessor board. Many startups go with a cubesat kit computer (e.g., Pumpkin or GomSpace) or even a homemade Raspberry Pi variant. But factors like radiation, fault tolerance, and limited reboot opportunities mean you can't treat it like a cloud server. One has to decide between flight heritage (older but proven processors) vs. modern performance (newer CPUs that might not have flown much).
- Electrical Power System (EPS): This includes batteries, solar panel regulators, and power distribution. Mismanaging this part can literally blow everything – say the payload draws a surge current the EPS wasn't designed for, you could brown out or destroy components. Every voltage rail and connector must be accounted for.

Each of these components likely comes from a different supplier, each with their own user manuals and quirks. Integration means getting all of them to play nicely together. If one vendor's spec is misread or one box is a millimeter off, the dominoes fall.
The Paperwork Nobody Tells You About
Beyond the engineering, a smallsat team ignoring "bureaucratic" docs is in for a rude awakening. To get a rideshare launch, you often must submit an Orbital Debris Assessment Report (ODAR) showing your satellite won't litter space or exceed casualty risk if it re-enters.
You'll also need spectrum licenses (coordinating radio frequencies through the ITU), export control approvals if hardware or data is going overseas, and various safety reviews. "Mission assurance" checklists – covering everything from flammability of materials, to battery safety, to whether your satellite has a tracking beacon – must be satisfied. These regulations are also not to be trifled with - a slip-up of handling ITAR technical data or hardware can lead one behind bars.
These processes can take longer than building the satellite itself! Startups new to aerospace sometimes learn the hard way that paperwork can delay a launch just as much as hardware problems.
Integrating the Payload (It's a Second Satellite)
Many smallsat efforts treat the payload (the instrument or sensor that actually does the mission, like a camera or radio) almost as an afterthought until the bus is done. That's a mistake – the payload has its own supply chain and integration challenges.

For example, a hyperspectral camera payload might require an RF communication chain to downlink large volumes of data: high-power amplifiers, software-defined radios (SDRs), FPGAs for signal processing, and specialized antennas. Each of those items might come from different vendors than the bus components.
They might require different testing (e.g., RF emissions testing in an anechoic chamber), and they often have high power draws that stress the bus EPS. A payload computer might run hot and need thermal management that wasn't in the original thermal model.
In effect, you are integrating two complex systems (bus + payload) that only come together late in the game. If the payload team and bus team haven't been in lockstep from day one, interface mismatches are almost guaranteed.
Testing Infrastructure Realities
In software, testing might mean unit tests and staging servers. In space hardware, it means shaking, baking, and zapping your satellite in every way imaginable – and this requires special (expensive) facilities.
Vibration tables simulate the violent rocket ride; thermal-vacuum chambers simulate the vacuum of space and temperature swings; anechoic chambers let you test antennas and radios without interference. Startups often underestimate how crucial and time-consuming this environmental testing is.
But skipping or skimping on it is courting disaster: Over 50% of CubeSats have failed on orbit (or never contacted ground) in large part due to inadequate testing before launch. Whether it's a loose screw that would have shaken out, or a radio that EMI jams in the vacuum of space, testing in mission-like conditions is the only way to catch it.
And unlike software where you can fix bugs after release, a satellite cannot be patched once it's out there. "Test as you fly, and fly as you test" is the mantra. The reality, however, is that many resource-strapped teams skip full testing – and the high smallsat failure rate is the price being paid.
Silicon Valley SaaS vs. Aerospace: A Cultural Collision
"Move Fast" vs. "Don't Break Things"
The Silicon Valley software mindset celebrates quick iteration – ship an MVP, update weekly, fail fast. Aerospace laughs (or rather, cries) at that idea, because physical hardware can't be iterated or deployed at that pace.
A SaaS engineer pushes new code to production and if it crashes, they patch it in hours. If a satellite malfunctions in orbit, it might be years (and tens of millions of dollars) before a replacement can fly.
This fundamental gap in agility leads to misaligned expectations. New space startup founders coming from software sometimes propose development timelines that make old aerospace hands roll their eyes – you simply cannot compress hardware build/test cycles the way you can with code sprints.
Every design change has ripple effects on mass, power, thermal, and needs re-testing. The cadence of "continuous deployment" hits a hard wall when each deployment is a literal rocket launch.
Understanding that hardware has a finality to it – a point of no return – is a mindset shift. Software folks eventually learn that in aerospace, caution is not laziness; it's survival. The challenge is to introduce some of software's flexibility without ever compromising the rigor needed for physical reliability.
Talent, Timelines, and Testing: Misaligned Mindsets
There's also a stark contrast in how talent and projects are managed. In the software world, a hotshot 10x developer can whip up a new feature overnight, and youthful prodigies often outshine veterans by rapidly adopting new frameworks.
In aerospace, experience is golden – the "graybeards" have hard-earned knowledge from seeing past missions succeed or fail. Silicon Valley newcomers might undervalue the specialized experts (like RF/FPGA engineers or orbital analysts proficient in GMAT, etc) because their skillset seems "arcane" compared to coding. On the contrary, their skillset is an area of unprecedented growth in demand and is critical to success of a space startup.
But come integration or anomaly time, those experts are the ones who know why your link budget is failing or how space radiation might be flipping your memory bits.
Similarly, timeline estimates cause friction. Software teams used to shipping a new app in 6 months might promise a satellite demo in 6 months – not realizing that just the radiation testing of a component can take that long.
Aerospace schedules account for things like procurement lead times, shipping delays, test iterations, regulatory hold-ups… factors often outside the team's control. This can be perplexing or frustrating to folks used to the relatively unconstrained domain of software.
And then there's testing: a SaaS startup might dedicate 10-15% of effort to QA testing; a space mission might spend 50% or more of the schedule on testing and reviews. To a move-fast hacker, that feels glacial and over-engineered. To an aerospace engineer, it feels just barely sufficient to sleep at night.
Cultural Failures in Action – Boeing Starliner Case Study
No story illustrates tech culture pitfalls in aerospace better than Boeing's Starliner. Here we have a traditional aerospace giant that stumbled in a very Silicon-Valley-esque way: software integration and testing failures.
In December 2019, Starliner's first uncrewed orbital test almost ended in catastrophe – a timing software error caused the spacecraft to miss its orbit insertion, and a separate critical bug (luckily caught just in time) could have fired the wrong thrusters during reentry.
The root cause? Inadequate end-to-end testing and perhaps a complacency that partial tests were "good enough" – an anathema in crew-rated spacecraft. Boeing had to do a full do-over of that test mission.

Then in August 2021, during the redo (OFT-2) attempt, they discovered 13 valves in the propulsion system stuck shut just hours before launch, scrubbing the mission. Such a basic hardware issue slipping through is a sign of process breakdown – moisture had gotten in and corroded the valves, a scenario that rigorous pre-checks should have caught.
Fast forward to 2023, and on the eve of finally flying astronauts, Starliner was halted again indefinitely: engineers found that certain parachute system components didn't meet safety margins and that hundreds of feet of wiring were wrapped in flammable tape – a detail overlooked for years. I wont mince my words or dance around the facts on this one: the first crewed Starliner mission endangered the lives of two American astronauts.
These "late discovery" problems are exactly what a strong engineering culture should catch early. Observers have pointed to managerial pressure and schedule-driven decisions overriding engineering concerns at Boeing – essentially, a cultural failure where a move-fast mentality (to catch up with SpaceX's Crew Dragon) trumped the cautious, methodical approach historically ingrained in human spaceflight.
The result was embarrassing delays and loss of trust. Starliner's saga underscores that no matter the pedigree, disregarding the fundamentals of testing, redundancy, and thorough review leads to failure.
It's a lesson both for old aerospace (don't get sloppy under new pressures) and for tech disrupters (this is what happens if you treat spacecraft like software apps). Hardware doesn't forgive just because your PowerPoint looked good or your CEO demanded a deadline. Reality wins, and culture must respect that.
Hard Truths
An Internal Memo to New Space Founders
After working at the intersection of software and spacecraft, certain patterns of misbelief keep emerging. Consider this an internal memo of hard truths for Silicon Valley entering aerospace:
Risk Aversion Masquerading as Rationality
In new space ventures, leaders often talk like bold innovators but then shy away from any plan that isn't a sure thing. This conservative reflex is sometimes dressed up as "being data-driven" or "prudent use of capital," but often it's just fear of the unknown.
True innovation in aerospace requires taking calculated risks – you can't demand Falon9 reliability and also claim to be "revolutionizing" things. If you find your team rejecting novel ideas by labeling them too risky without deep analysis, check if it's legitimate rationale or just knee-jerk aversion.
Aerospace is risky by nature; embracing a calculated amount of that (with eyes open) is part of the game.
Short-Termism and Warped Funding Expectations
Many tech investors are impatient – they want 10x returns in 2-3 years, fueled by the precedent of software unicorns. But aerospace timelines don't conform to VC fund cycles.
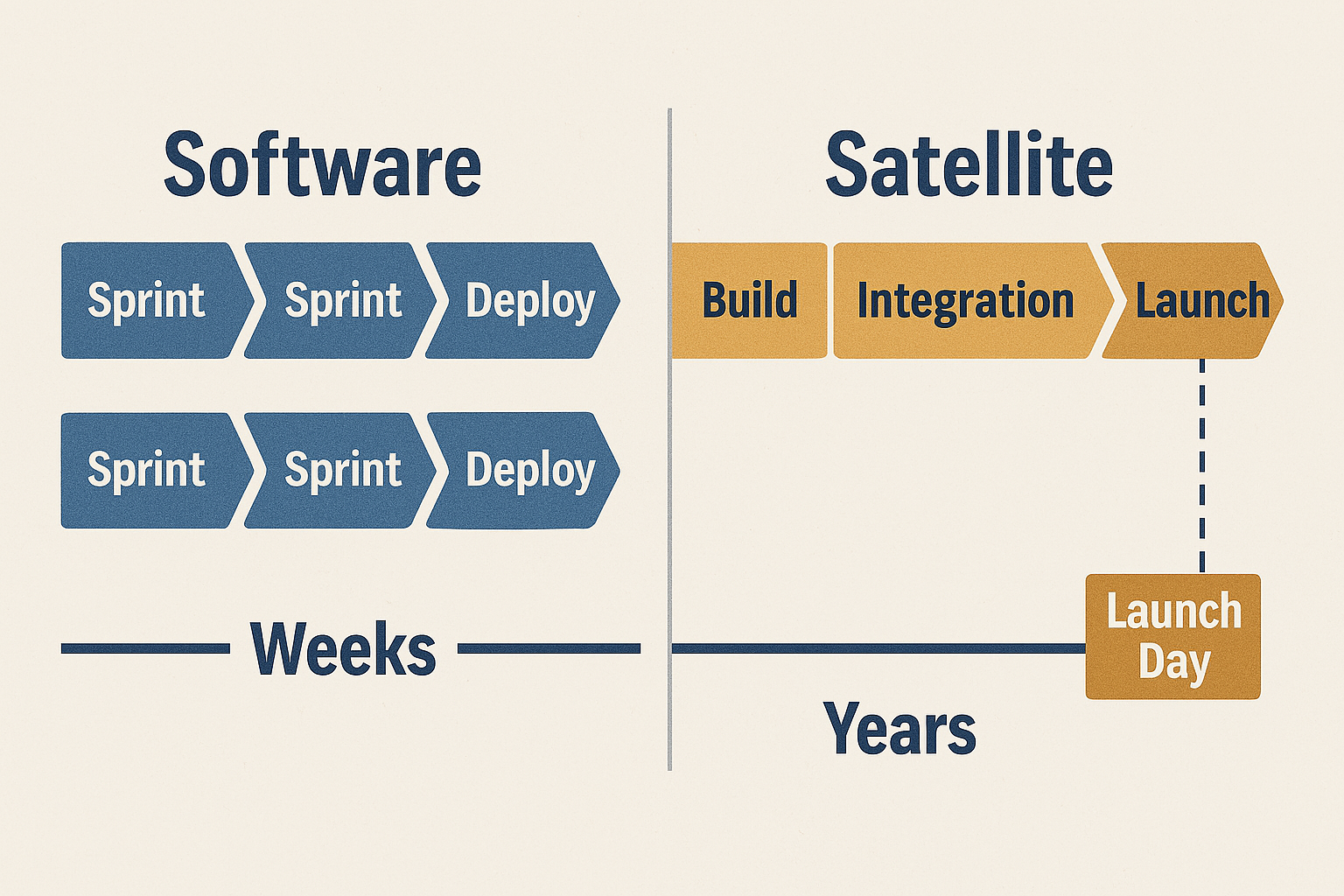
It can take a few years just to go from paper design to a working prototype in orbit, and longer to scale. Companies and investors that aren't prepared for this often promise unrealistic milestones to secure funding, then scramble or pivot frantically when they can't meet them.
We've seen a major LEO constellation company like OneWeb go bankrupt after spending $3.4 billion because it still needed more time and money to finish deploying its network – something early investors balked at, pulling out when quick success didn't materialize.
Serious space endeavors need patient capital and investors who understand that value accrues over decades, not quarters. Beware of funding strategies that rely on Silicon Valley speed; misaligned expectations can kill great technology just as it's getting started.
Inexperience with Scarcity and Specialized Talent
In software, if you need more computing, you spin up another AWS instance. If you need more developers, you can usually hire from a huge pool of general coders. In aerospace, key resources are inherently scarce and expensive.
You can't conjure more bandwidth on the Deep Space Network out of thin air, or magically produce an alternate rocket launch slot when the manifest is full. The talent pool is also niche: the number of people who've designed GHz-range space radars or hypergolic propulsion systems is small, and they're likely already booked.
Newcomer founders often haven't experienced true scarcity – they underestimate how one missing specialist or a limited test facility can bottleneck the whole project. This inexperience leads to optimistic planning ("surely we can find someone to build this custom flight computer by next month?") that doesn't survive contact with reality.
Successful new space teams either recruit experienced mentors or become avid students of the old school, to learn where the hard limits and choke points are.
Moral Squeamishness Around Defense/Dual-Use Tech
A notable cultural difference – many tech folks carry an ethical hesitation about building technology for warfare or defense, whereas the space and aviation industries have long, intertwined relationships with the military (for funding and for technological advancement).
We've seen public examples of this tension, most notably Google's internal rebellion against the Pentagon's AI contract (Project Maven) in 2018, where over 3,000 employees petitioned and several resigned rather than develop technology for drone surveillance. While individual beliefs are understandable, the reality is that engineers ideologically opposed to projects supporting U.S. defense and allied security will likely find themselves fundamentally incompatible with much of the aerospace and defense sectors.
It's a personal choice, but one that needs confronting early. The reality is much of the money in "New Space" (and certainly in defense) is coming from government security needs. A company that refuses on principle to ever do defense work may find its financial runway far shorter.
The key is alignment and transparency: if you're not willing to go after defense dollars, ensure your investors and team know that up front (and have a plan to survive on commercial markets alone).
If you are willing, set ethical guardrails. But don't pretend the issue doesn't exist. Nothing will sink a team faster than an internal revolt because leadership quietly took a military contract that the rank-and-file hate. Decide where you stand, communicate it, and build accordingly.
Lack of "Survival Scars"
In Silicon Valley, a bad day might mean a server outage that gets fixed by evening, or a pivot when an app feature flops. In space, a bad day can mean $100 million of hardware is now space junk because of one oversight.
The veterans in this field carry what we call "survival scars" – memories of missions that failed or nearly failed, and the humbling lessons learned. These might be literally watching a rocket explode on the pad, or deploying a satellite that never calls back (silence… forever).
Those experiences instill a profound respect for Murphy's Law and the need for contingency planning. Many newcomers simply haven't been through a true space catastrophe; their risk models are based on successes or simulations, not that visceral feeling of hearing nothing on the ground station when you expected your satellite's beacon.
Without those scars, it's easy to be overconfident. The antidote is to actively seek out stories of failure – read the post-mortems of missions like NASA's Hitomi telescope (lost to a software/config error causing it to spin out of control) or the countless CubeSats that died due to power system misconfigurations.
Assume that any mistake that can happen, eventually will. Cultivate a culture where people acknowledge their mistakes and share lessons, so the organization as a whole gains "scar tissue" even if individuals are new.
In aerospace, wisdom is written in blood (or broken hardware) – never forget that.
Conclusion: Space Is Hard – Technical Experience and Alignment are More Critical than Flashy Ideas
The new wave of space and defense startups cannot win with swagger and software savvy alone – they need a deep respect for the unforgiving physics and logistics of hardware. The hidden fragility of space systems – from supply chains and testing, to integration and operations – means that experience matters.
Teams that blend youthful software-style ingenuity with seasoned aerospace wisdom will have the best shot at success. This means founders and investors must set realistic timelines and fund accordingly, valuing the "boring" expertise of mission assurance and systems engineering as highly as the flashy AI or app talent.
It means engineers must internalize that once a rocket launches, your code and hardware become one, and there's no rolling back a bug in a solder joint. Culturally, it requires ditching any arrogance at the door: whether you're a Stanford CS grad or a former Google exec, space will humble you – better to embrace humility from the start than be taught by failure in orbit.
At the end of the day, delivering in New Space and defense isn't just about clever tech or big ideas; it's about execution under constraint. The companies that will prevail are those that marry Silicon Valley's creativity and speed with aerospace's rigor and resilience.
That means celebrating test engineers and supply chain managers alongside coders. It means having leadership that rewards honesty about problems more than glossy hype. And it means having the fortitude to do things the right way even when no one is watching – because the only judge that matters is physics, and physics always gets the last word.
For those bold enough to venture into this realm: get aligned and get serious about the details. Respect the harsh lessons of those who came before.
That's how you avoid becoming another cautionary tale, and instead build something that truly soars.
